
Hidden Markov Model (HMM)#
Introduction#
The HMM is a popular model for studying time series data. The HMM has been used successfully to study neuroimaging data [1-8].
This model consists of two parts:
A hidden state (also known as latent variable) whose dynamics are governed by a transition probability matrix.
An observation model, which is the process of generating data given the hidden state.
Generative Model#
A generative model can be written down mathematically by specifying the joint distribution of observed and latent variables. The joint probability distribution for the HMM generating a sequence of data is
where \(x_{1:T}\) denotes a sequence of observed data (\(x_1, x_2, ..., x_T\)) and \(s_{1:T}\) denotes a sequence of hidden states (\(s_1, s_2, ..., s_T\)).
\(p(x_t | s_t)\) is the probability distribution for the observed data given the hidden state. In this package, we use a multivariate normal distribution to specify this distribution.
where \(m_k\) and \(C_k\) are state means and covariances and \(k\) indexes the state that is active.
\(p(s_t | s_{t-1})\) is the temporal model for the hidden state. Because the probability of the next state only depends on the current state (known as the Markovian constraint), this conditional probability distribution can be represented as a matrix.
The generative model is shown graphically below. The hidden states are the grey nodes and the observed data are white nodes. Arrows connect variables that are conditionally dependent.
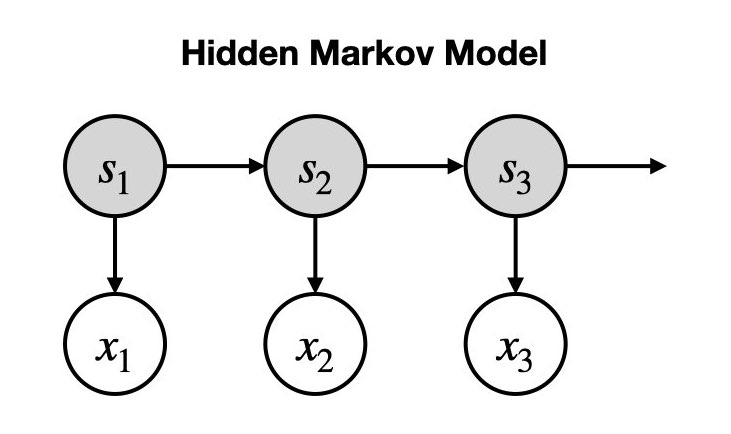
Inference#
The process of inference is to learn model parameters from observed data. In our case, the model parameters are:
The hidden state at each time point, \(s_t\).
The transition probability matrix, \(A_{ij} = p(s_t = i | s_{t-1} = j)\).
The initial state probabilities, \(\pi_1 = p(s_1)\).
The observation model parameters: state means, \(m_k\), and covariances, \(C_k\).
We use a Bayesian inference method called the Expectation-Maximization (EM) algorithm to learn these parameters. In short:
We randomly initialize the model parameters.
E-step: we use the current value of the model parameters \(\{ A_{ij}, \pi_1, m_k, C_k \}\) to estimate the state probabilities \(q(s_t)\) (posterior).
M-step: we use the state probabilities \(q(s_t)\) from the E-step to update the model parameters \(\{ A_{ij}, \pi_1, m_k, C_k \}\).
After we have trained the model, we take the most likely value from \(q(s_t)\) as our estimate for the model parameters (this is known as the MAP estimate).
We do the above for small subsets of our entire training dataset (batches), which leads to noisy updates to the model parameters. Over time they converge to the best parameters for generating the observed data.
The process of inference is also known as ‘training the model’ or ‘fitting a model’.
HMM in osl-dynamics#
This package contains a Python implementation of the HMM. In this implementation we perform Bayesian inference on the hidden states, \(s_t\), but learn point estimates (i.e. not Bayesian) for all the other parameters, this includes the transition probability matrix and state means and covariances. Given the transition probability matrix, state means and covariances are global parameters (the same for all time points), modelling their uncertainty is less valuable, whereas the uncertainty in the hidden state may be different at different time points.
A derivation of the cost function used to train the HMM in osl-dynamics is here. Note, we use different symbols in this derivation compared to the previous section.
HMM-MAR Toolbox#
Our group has previously implemented an HMM in MATLAB: HMM-MAR. The model in HMM-MAR is fully Bayesian, i.e. it learns the uncertainty in all model parameters.
Canonical HMM Networks#
A set of canonical HMM networks trained on a large MEG dataset are available in the Canonical-HMM-Networks repository. These can be used as a reference or starting point for HMM analyses.
Post-hoc Analysis#
After we fit an HMM we’re often interested in interpreting the hidden states. We typically do two types of analysis: studying statistics that summarise the hidden state time course (called summary statistics) and re-estimating spectral properties from the training data given the state time course. These are discussed below.
Summary Statistics#
It is common to look at four summary statistics:
The fractional occupancy, which is the fraction of total time that is spent in a particular state.
The mean lifetime, which is the average duration of a state visit. This is also known as the ‘dwell time’.
The mean interval, which is the average duration between successive state visits.
The switching rate, which is the average number of visits to a state (i.e. activations) per second.
Summary statistics can be calculated for individual subjects or for a group. See the HMM Summary Statistics tutorial for example code of how to calculate these quantities.
Spectral Analysis#
When we train using the time-delay embedding (see the Data Preparation tutorial for further details) we can learn spectrally distinct states. I.e. states that exhibit oscillatory activity at different frequencies. We can estimate the power spectral density (PSD) of each state using the unprepared training data (i.e. before time-delay embedding) and the hidden state time course. We normally use a multitaper approach for this. This involves a few steps:
Multiply the (unprepared) training data by the hidden state time course (or state probability time course). This essentially picks out the time points that correspond to when the state is active.
Split the time series into windows with no overlap. Typically we use twice the sampling frequency for the window length to give us a frequency resolution of 0.5 Hz.
Multiply each window by a number of ‘tapers’ (hence the name ‘multitaper’) to give a number of tapered windows.
For each tapered window, calculate the Fourier transform and square to give a PSD for the tapered window. Next, we average the PSD of each tapered window to give an estimate of the PSD of the window.
Then, average over each window’s PSD to give an estimate of the PSD of the entire time series.
The above is performed in the osl_dynamics.analysis.spectral.multitaper_spectra() function in osl-dynamics.
We find high frequency activity (above ~25 Hz) sometimes leads to noisy estimates for coherence networks. To remove this noise, we often use a non-negative matrix factorization (NNMF) approach to separate different bands of oscillatory activity. These bands are sometimes referred to as ‘spectral components’. The HMM Plotting MEG Networks tutorial goes into this in more detail.
When calculating power and coherence maps for HMM states the multitaper and NNMF approach is recommended.
Fisher kernel#
The Fisher kernel can be used to characterize the similarity between subjects given the generative model. This can be used for downstream supervised learning tasks using for example kernel ridge regression and kernel SVM (support vector machine). This gives a more principled way to perform predictions than using “handmade” features like the summary statistics and it has the advantage of tuning the importance of each parameter in the generative model automatically in a prediction task.
For a derivation of the Fisher kernel see here.
References#
D Vidaurre, et al., Discovering dynamic brain networks from big data in rest and task. Neuroimage, 2018.
A Baker, et al., Fast transient networks in spontaneous human brain activity. Elife, 2014.
D Vidaurre, et al., Brain Network Dynamics are Hierarchically Organised in Time. PNAS, 2017.
D Vidaurre, et al., Spontaneous cortical activity transiently organises into frequency specific phase-coupling networks. Nat. Commun. 2018.
J van Schependom, et al., Reduced brain integrity slows down and increases low alpha power in multiple sclerosis. Multiple Sclerosis Journal, 2020.
T Sitnikova, et al., Short timescale abnormalities in the states of spontaneous synchrony in the functional neural networks in Alzheimer’s disease. Neuroimage: Clinical, 2018.
A Quinn, et al., Task-evoked dynamic network analysis through hidden markov modelling. Frontiers in Neuroscience, 2018.
C Higgins, et al., Replay bursts in humans coincide with activation of the default mode and parietal alpha networks. Neuron, 2021.